Chaos isn't a pit. Chaos is a ladder.
Rui Qiu
Updated on 2021-09-26.
via GIPHY
Without a doubt, cleaning is painful. But hopefully, it will provide some convenience later.
For this part of the portfolio, not only was the collected data cleaned, more data was introduced into the game. Compared with the collection two weeks ago, it expands in the following three ways.
- The hand-tracked play-by-play NBA data provided by PBP Stats only includes three-point shooting attempts, which only account for roughly one-sixth of the total shooting data from the 2020-2021 regular season. More data categorized by the team has been pushed to the repository.
- Some sports news articles are extracted with NewsAPI in order to fulfill the objective of cleaning text corpus with Python. There are no intermediate files saved. The final Document-term matrices are stored as text files instead.
- As time goes by, the data collection of the top 10 posts in Reddit’s /r/NBA subreddit is growing day by day.
Section 1: Record cleaning with R
Script: pbp-cleaner.R
Data (raw): data/nba-pbp/2020-raw-by-team
Data (cleaned): a complete list of shots, a list of player and id, group by team, group by opponent
As mentioned above, the previous data is only a partition of the data of interest. After retrieving more data from the same resource, a directory of all teams’ shot attempts from the 2020-2021 regular season are ready for cleaning.
All the CSV files are row-binded into one large tibble. A glimpse() would
demonstrate the overall structure of such tibble.
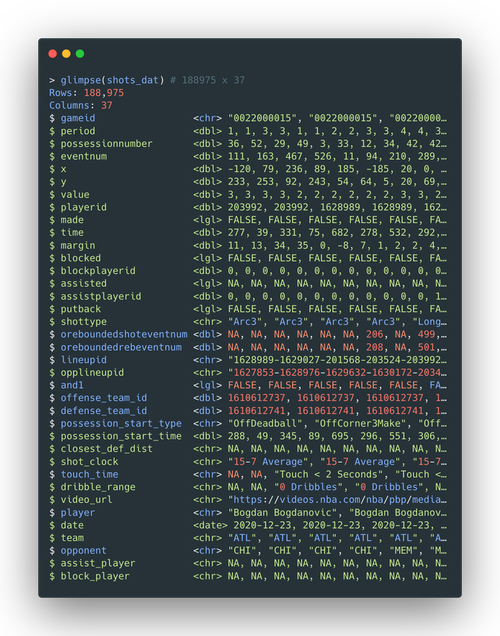
The shots_dat tibble has in total 188975 rows of shots recorded and 37
variables for each shot.
Remove redundant variables
Some of the variables are not that appealing, either because they don’t provide much information
for
building our expected score/threat model, or they are just ids of some other variables. They are
based
on the
common fact that the current roaster of NBA players does not contain players sharing the same name.
Therefore,
removing the ids does not matter too much.
The following variables are discarded: gameid,
eventnum, oreboundedshoteventnum,
oreboundedrebeventnum, offense_team_id,
defense_team_id, possession_start_type,
possession_start_time, blockplayerid,
assistplayerid.
Reorder remaining variables
Usually, relocate() fits the need here. However,
select() would be a better choice since all variables might need a
reconsideration
before moving on to the next stage.
By doing so, the variables are grouped into eight subgroups below:
- Offensive player(s):
player,playerid,team,assist_player,lineupid - Defensive player(s):
opponent,block_player,opplineupid - Time:
date,period,possensionnumber,time,shot_clock - Game:
margin - Location:
x,y - Shot setup:
shottpye,assisted,putback,closest_def_dist,touch_time,dribble_range - Shot result:
value,made,blocked,and1 - Miscellaneous:
video_url
By far, there is a lethal defect in this collection of data compared with the previous one: there are no traces of assist or pass coordinate in this one. That is to say, to build a time-based or location-based Markov Chain of ball movement before scoring, we need to investigate something like a game log in detail to retrieve those pass locations. This is really disheartening.
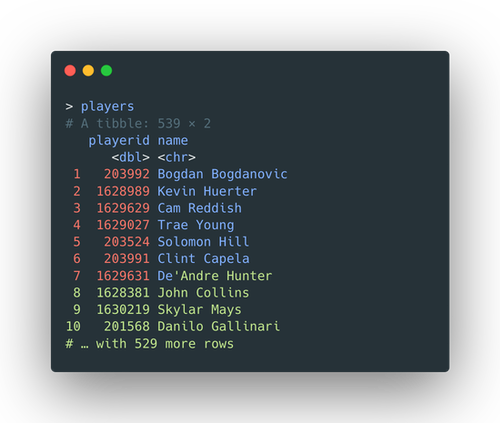
Get a list of player-id for reference
This step is not urgent but probably necessary. A list of playerand
playeridis exported into a CSV file. Even though some
ids
variables have been deleted, the lineupid and
opplineupid
are still string variables with playerid separated by hyphens
(-).
Check legitimacy
Ideally, this step is where outliers and
NAs are removed. There were lots of “trial and error” in the actual
cleaning
procedure. For the following variables, NAs are strictly prohibited, simply because NAs do not make
sense in
those: playerid, player,
team,
lineupid, opponent,
opplineupid,
date, period, time,
margin, x, y,
shottype, putback, value,
made, and1.
For the rest of the variables, NAs might be just the suitable candidates for some cells. For
instance,
if
a defender executed no block attempt, it should be NA instead of
FALSE in blocked.
Additionally, possessionnum is deleted as well, since it is the
sequential
order number of the event in-game, rather than “how many passes before the shot.”
Then, a summarytools::descr() can be performed to get some descriptive
statistics.
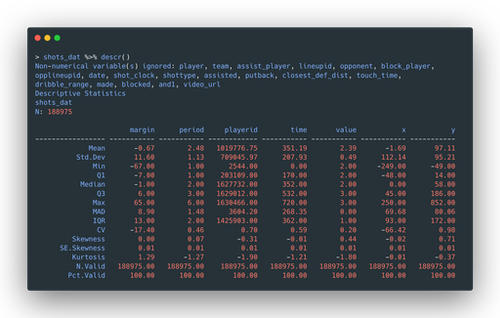
The real deals are the legitimacy checking for variables. In other words, if things don’t add up, they will be examined or may be thrown away. What do they look like?
- Check if
time(the remaining seconds of a quarter, calledperiodin the data, though) is between 0 and 720. - Check if a shot is
made, but no one assisted (is.na(assisted)). - Check if a shot is
blocked, but no block player is recorded (is.na(block_player)). - Check if a shot is
made, butblockedsimultaneously, which is extremely unlikely in real life. - Check if a shot is
assisted, but no assist player is recorded (is.na(assist_player)).
There should definitely be more common facts to check. Luckily, one entry error was spotted when checking the fifth condition.
The Philladelphia 76ers player Tobias Harris was assisted by Ben Simmons, but Simmons’ name was
recorded
as NA here. This was probably caused by a mixed-up
team
and opponent variables. Harris should be playing for
PHI
and against DET. It was fixed with some manipulations.
Create new features
As mentioned above, new features are created by splitting a string of ids
connecting with each other.
Another glimpse() shows the shots_dat is now a
188975
by 34 tibble.
If the next step is analysis or model building, there are more standard procedures to do. For example, turning some character variables into factors. Nevertheless, saving the tidy data frame into another text file will counteract the effort.
Save cleaned data
The cleaned data is saved in one file as a whole and grouped by team and
opponent, then split into multiple sub-files. The new data is not that
unbelievably
large (60Mb). Splitting into various files might be overkill.
Section 2: Text cleaning with R
Script: reddit-cleaner.R
Data: data/nba-reddit/ raw data stored in .RDS, cleaned data stored in .csv.
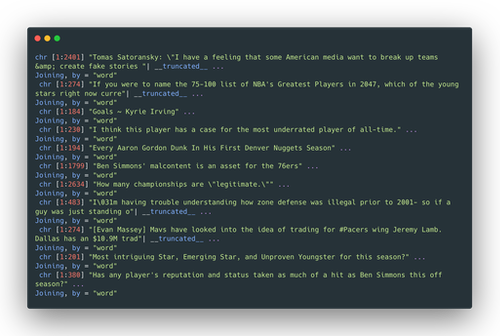
The text data scraped from the subreddit is stored in temporary RDS files, named when scraping is performed.
The daily text data varies in size and length:
The logic here is clear:
- Iterate all files ending with
.RDSin the directory. - Load one file at a time to get the R list object inside it.
- Trim all variables except the text data (the thread title, thread text, and comments).
- Turn the structure into a corpus.
- Process the corpus by removing whitespaces, punctuations, stopwords, and lowering the letters.
- Last but not least, use
tidytext::tidy()to transform the corpus back to the familiar tidied tibble. - No labels are attached to the text data for topic modeling. Instead, the Bag-of-Words are generated and stored.
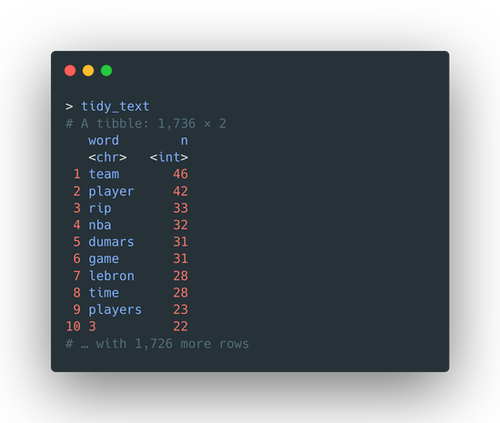
The final look of a daily Reddit text data is like this:
cron job update
Script: cron-job.r
Since the Reddit scraping script runs once a day in the evening, it might be a good idea to update
it
with text processing commands, such that the tidy text data will be saved to remote as well.
Besides,
the line
that saves a temporary list into .RDS file is removed.
No issue is detected in the automation.
Section 3: Record cleaning with Python
Script: tweet-clean.ipynb
Data (raw): data/nba-tweets/player-accounts-br.csv, data/nba-tweets/player-accounts.csv
Data (cleaned): data/nba-tweets/player-accounts-cleaned.csv
The raw data of consists of two files:
player-accounts-br.csvcontains current and retired players’ names and their Twitter account handles.player-accounts.csvincludes current players’ name and more metadata such as follower number and register time.
The target output for this part is a list of name-handle pairs with no duplicates. The cleaning procedures are in the following order:
- Load two files individually.
- Keep names and handles as the only two columns.
- Rename the columns as
nameandaccountso that the two data frames can be binded together. - Remove rows with
NaNinaccount. - Remove duplicate rows which are identical in both
nameandaccount. - Investigate some rows with a duplicate
namebut a differentaccount. This could be either the player changed their handles, or the initial entries were simply incorrect. Remove the outdated/incorrect records.
| name | account | |
|---|---|---|
| 295 | Deonte Burton | DeonteBurton |
| 618 | Deonte Burton | DeeBurton30 |
| 1065 | Devin Booker | DevinBooker31 |
| 1303 | Devin Booker | DevinBook |
| 1406 | Marcus Thornton | M3Thornton |
| 2184 | Marcus Thornton | OfficialMT23 |
| 485 | Mike Conley | mconley11 |
| 1683 | Mike Conley | MCONLEY10 |
| 1992 | Tony Mitchell | TonyMitchUNENO |
| 1993 | Tony Mitchell | tmitch_5 |
- Investigate some other rows with a duplicated
accountbut a differentname. There is no omnipotent solution to this. But the rough idea is to split thenameby whitespace and remove the ones of length 1.
| name | account | |
|---|---|---|
| 1442 | Justin James | 1JustinJames |
| 212 | JJ | 1JustinJames |
| 2224 | Andrew Wiggins | 22wiggins |
| 397 | andrew wiggins | 22wiggins |
| 1594 | Kent Bazemore | 24Bazemore |
| ... | ... | ... |
| 1378 | Willy Hernangómez | willyhg94 |
| 490 | Thad Young | yungsmoove21 |
| 2247 | Thaddeus Young | yungsmoove21 |
| 38 | Zhaire | zhaire_smith |
| 1408 | Zhaire Smith | zhaire_smith |
- Remove all rows with emojis 😆🔥٩(‿)۶ in
name. - Keep the first one if there are still duplicate pairs.
- Save the cleaned data frame as a CSV.
Section 4: Text (CSV) cleaning with Python
Script: tweet-clean.ipynb
Data (raw): data/nba-tweets/player-tweets.csv, data/nba-tweets/player-tweets-2.csv
Data (cleaned): data/nba-tweets/tweets-corpus-cleaned.csv
Two CSV files, each containing around 500 tweets, are loaded.
The label picked here is the last column of CSV tweets data, urls which
stores
a list of dictionaries of URLs that appeared in a tweet. A funny thing about loading the CSV into a
pandas
data frame is that the “list” is loaded as a string type but starting with a
[
and
ending with a ]. The trick to determining if there is a URLis to check if
the
length
of url is equal to 2.
CountVectorizer is then utilized to generate the Bag-of-Words from the data frame.
Note
that
only a maximal number of 500 features are kept.
Then the Document-term matrix is generated, with a column of boolean variable
contains_url attached to the first column.
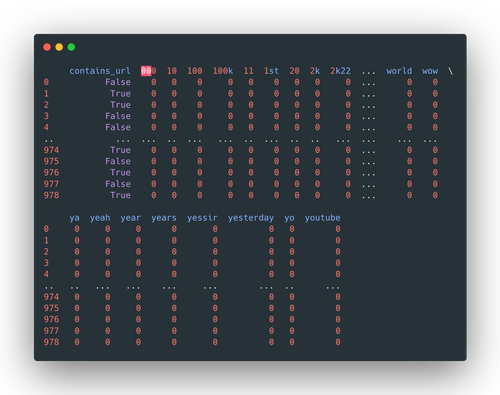
Afterward, it is saved to the destination directory.
Section 5: Text (corpus) cleaning with Python
Script: tweet-clean.ipynb
Data (raw): data/nba-news-source/news-2021-09-25.csv
Data (cleaned): data/nba-news-source/dtm-2021-09-25.csv
Strictly speaking, there is no text corpus suitable for text preprocessing based on the current data collection. A quick and dirty approach is to apply NewsAPI and grab some news articles from different sources.
Exposing API in the script is a bad idea.
The data contains news headlines from August 25 to September 25, 2021, with a range of sources of SB Nation, ESPN, Fox Sports, and Bleacher Report.
| Source | Date | Title | Headline | |
|---|---|---|---|---|
| 0 | ESPN | 2021-09-02 | What if Skills that could change the games of ... | What if Luka was automatic from the stripe Wha... |
| 1 | ESPN | 2021-09-02 | NBA eyes strict rules for unvaccinated players | Unvaccinated NBA players will have lockers as ... |
| 2 | ESPN | 2021-09-21 | Redick to retire after seasons in NBA | JJ Redick who played for the Pelicans and Mave... |
| 3 | ESPN | 2021-08-25 | Lapchick NBA sets high bar for health policies... | The NBA has played a leading role in men s pro... |
| 4 | ESPN | 2021-09-24 | Sources Ginobili returning to Spurs as advisor | Four time NBA champion Manu Ginobili one of th... |
| ... | ... | ... | ... | ... |
| 95 | Bleacher Report | 2021-09-14 | NBA Re Draft Does Jayson Tatum or Donovan Mitc... | In the instant analysis culture of today s spo... |
| 96 | Bleacher Report | 2021-09-15 | Ben Simmons Rumors ers Expect PG to Play Next ... | Despite a href https nba nbcsports com report ... |
| 97 | Bleacher Report | 2021-09-14 | NBA Trade Rumors John Wall Rockets Mutually Ag... | John Wall and the Houston Rockets have reporte... |
| 98 | Bleacher Report | 2021-08-25 | Woj Mike Budenholzer Bucks Agree to New Year C... | Mike Budenholzer will remain with the Milwauke... |
| 99 | Bleacher Report | 2021-09-22 | NBA Offseason Moves with the Most Bust Potenti... | Every offseason transaction carries downside r... |
Due to the API limit, only 100 articles can be retrieved at a time.
The features are extracted from the Headline and used to generate another
sparse Document-term matrix. Naturally, the Source column is attached to
the
end as
the label.
Conclusion
There is nothing too spectacular to talk about in data cleaning. The cleaning process itself is very messy and chaotic, to be honest. But it would definitely help later. It is just like a ladder.