Where are these five players fitting in?
Rui Qiu
Updated on 2021-10-11.
Please refer to the last chapter for more details. The script used, however, is still the one for clustering.
- GitHub repo: box2box
- R script for clustering and predictions: clustering.R
Background
Adding some new record to an existing clustering is not always a good idea since clustering itself is an unsupervised learning. It heavily relies on the “training” data. So here’s the best case: if the newly added data are not very extreme, nor are they very influential in quantity (say greater than 10% of the previous data), then they are good. Otherwise, the centroids might better be recalculated.
Method
Before doing anything practical, let’s take a look at the current clustering for optimal value
$\ k=3$.
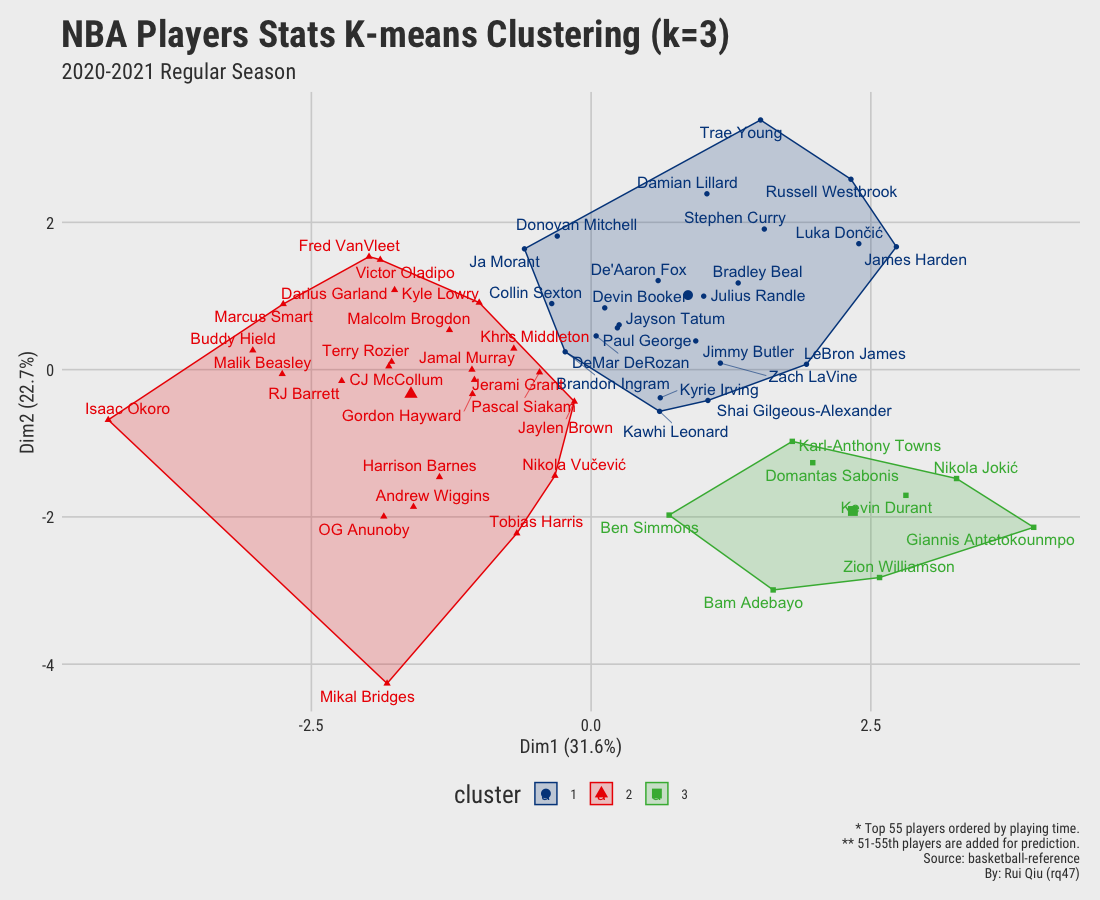
Open in new tab to see in full size.
The KNN (k-nearest neighbors) algorithm is the perfect solution to the introduction of new individuals. Specifically, the existing 50 players are grouped into the following three groups:
| Group 1 | Group 2 | Group 3 |
|---|---|---|
| 21 | 22 | 7 |
The KNN calculates the distance between labeled training data and the new instance through some similarity measures, e.g., the Euclidean distance. Then the sample will be distributed to the cluster that is the closest to.
Results
The new addition of data is five players ranked by playing minutes from the 51-55th place. And the KNN predictive results are:
[1] 1 1 1 1 3
Levels: 1 2 3
This means four of them are predicted to be in Group 1, and the last one in Group 3.
Visually, a scatter plot would do the explanation. The newly added player names are enlarged in text labels.
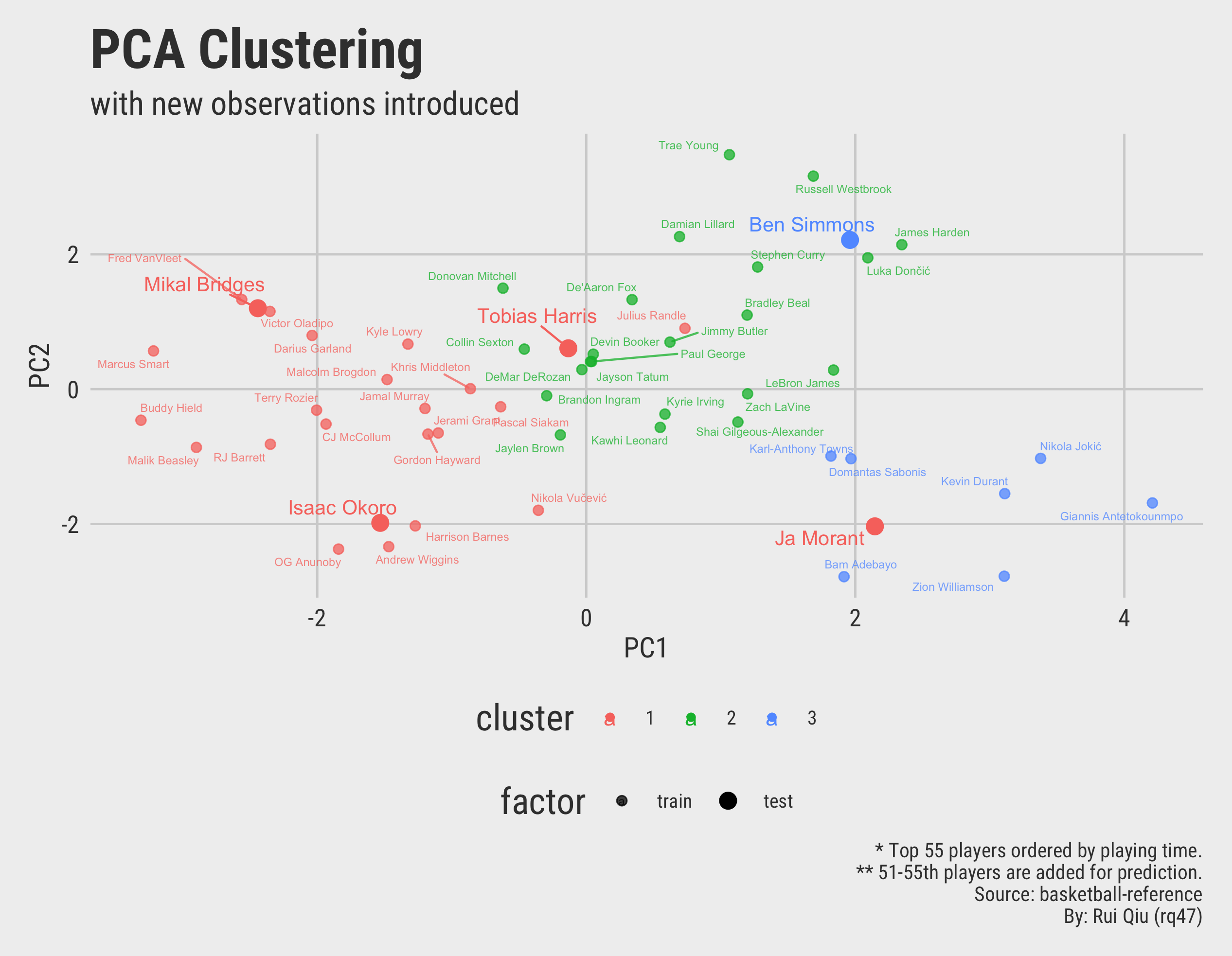
Open in new tab to see in full size.
Discussion
As mentioned above, using clustering as a predictive model is not always the first choice for classification. The KNN should be based on some real-labeled data instead of using clustered groups as the "labels."
Furthermore, the prediction made by KNN based on $\ k=3$ clustering is problematic:
- Ben Simmons is actually located within cluster 2 but marked as cluster 3.
- Ja Morant is marked as cluster 1 but resides within cluster 3.
- Tobias Harris, along with Julius Randle from the previous data set, though marked as cluster 1, but indeed stay closer to cluster 2.
These are all drawbacks of clustering NBA players by their statistics, which are eventually discussed in the summary part of Part 1.